

今日Twitterのライン上にたくさん流れていた話題がストロンチウム。
nsr.go.jp/committee/yuushikisya/tokutei_kanshi_wg/20140124.html
このページ「原子力規制委員会」のホームページなんですが、
ここで「ストロンチウム」の情報を検索しようとしても、
なぜか結果が0件になってしまう、というんですね。
そこでトを卜(ぼく)に、
ロを口(くち)にして
「ス卜口ンチウム」と検索するとデータがゴロゴロ出てくる、
というリツイートがたくさん流れてきました。
ほんとかなぁ?と思って試しに検索してみたのですが、
普通に検索で1300件あまりの情報が出てきます。
あれ?どういうこと?
ガセだったの?それとも原子力規制委員会が、このツイートに気付いて直したってこと?
と思って、
念のため「ス卜口ンチウム」でも検索すると、
これが、ちゃんと2件引っかかるんですね。
んー、ちょっと真相がよくわからないのですが、
2件Hitするということは、
卜(ぼく)と口(くち)をわざわざ使って入力した人がいる、
というのは確かですよね。
これ、PCが勝手にこのような変換をすることは非常に考え辛いですから。
よくよくツイートを遡ってみると、
pdfをOCRで読み込んだ時に変換ミスしたのかも?
というツイートも見つかりました。
まぁそうであればなんとなく納得もできますが、
そうなると、逆に、
「検索したら0件だった」と言った人が間違っていたということになっちゃいます。
間違って検索をかけたのか、
もしくは、なにか意図があってそのように流したのか…?
んー、もう少し遡ってみたら、
どうやら発端はここだったようです。
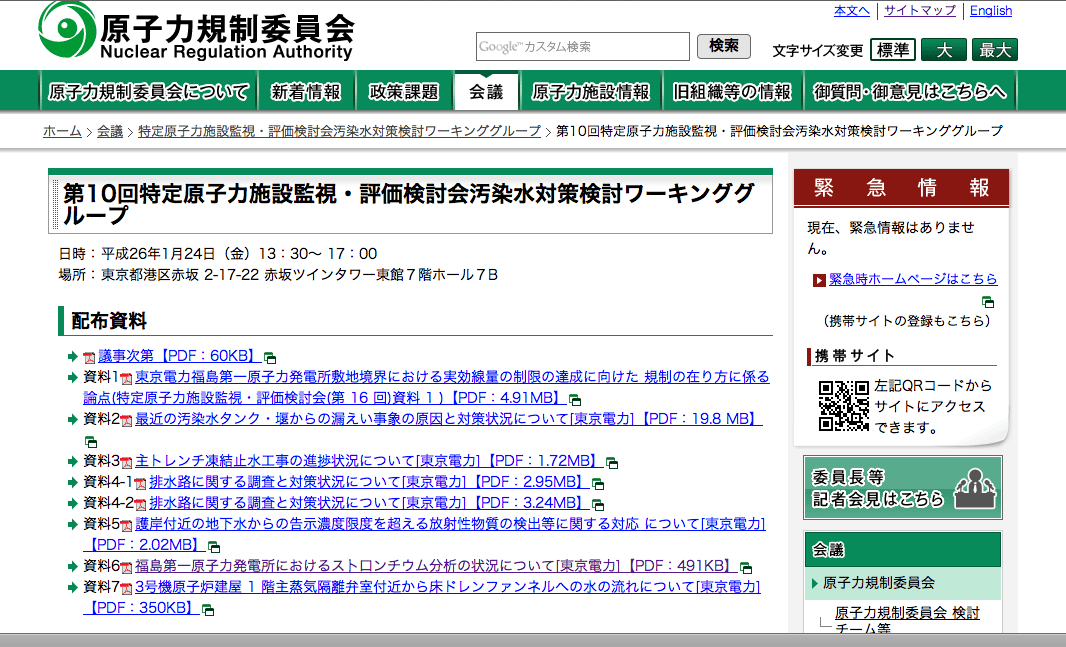
この資料6のストロンチウムの文字がぼくとくちでできている。
もうソースも調べちゃいましたよ。
これはOCRの読み込みミスじゃないですね。
つまり、サイト内検索した結果、全部がぼくとくちになっているわけじゃなく、
このトップページの文字が検索よけの工作がされているんじゃないか、
というのがポイントだったようです。
つまり、サイトの上部にある検索窓を使うのではなく、
ブラウザで表示ページ内を検索した結果が0だった、というのが正しい情報だと思われます。
Twitterは、文字数も少ないし、誤解を生む場合もあるんでしょうね。
何にしろ、勝手に解釈しないで調べないといけないなぁと痛感しました。
それにしても、このトップページはちょっとなぁ………




